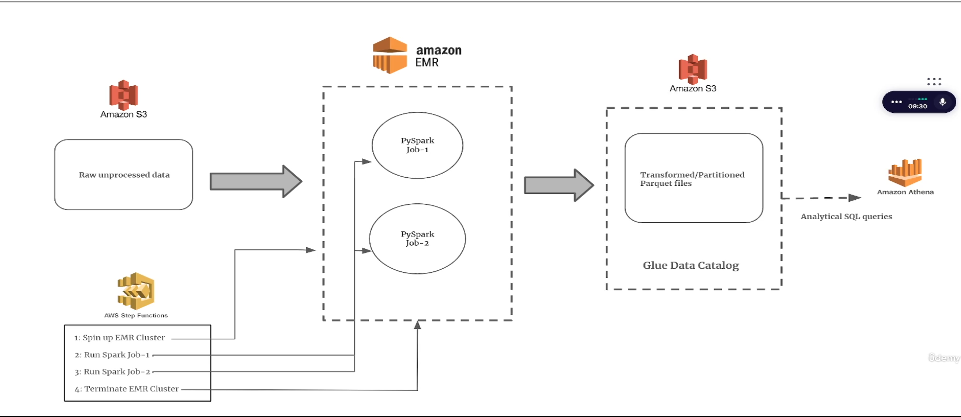
EMR Project use :
EMR - USE for spark job
S3 - storage and data lake
GLUE & Athena - SQL Engine
Step function ( link ) - data orchtation
CI/CD - github action
data set :
- retenal traction
- vechile
- user
- location
project :
1) emr spark job creating the matrix and writing output in s3.
2) we use the glue for traction the job and run query in atena then moving to redshift.
3) s3 used for data-bucket/csv file as well as code-bucket/.py code.
4) Step function creating the spark-emr-cluster and runing job and then terminating spark-emr-cluster.
5) used ci/cd github action